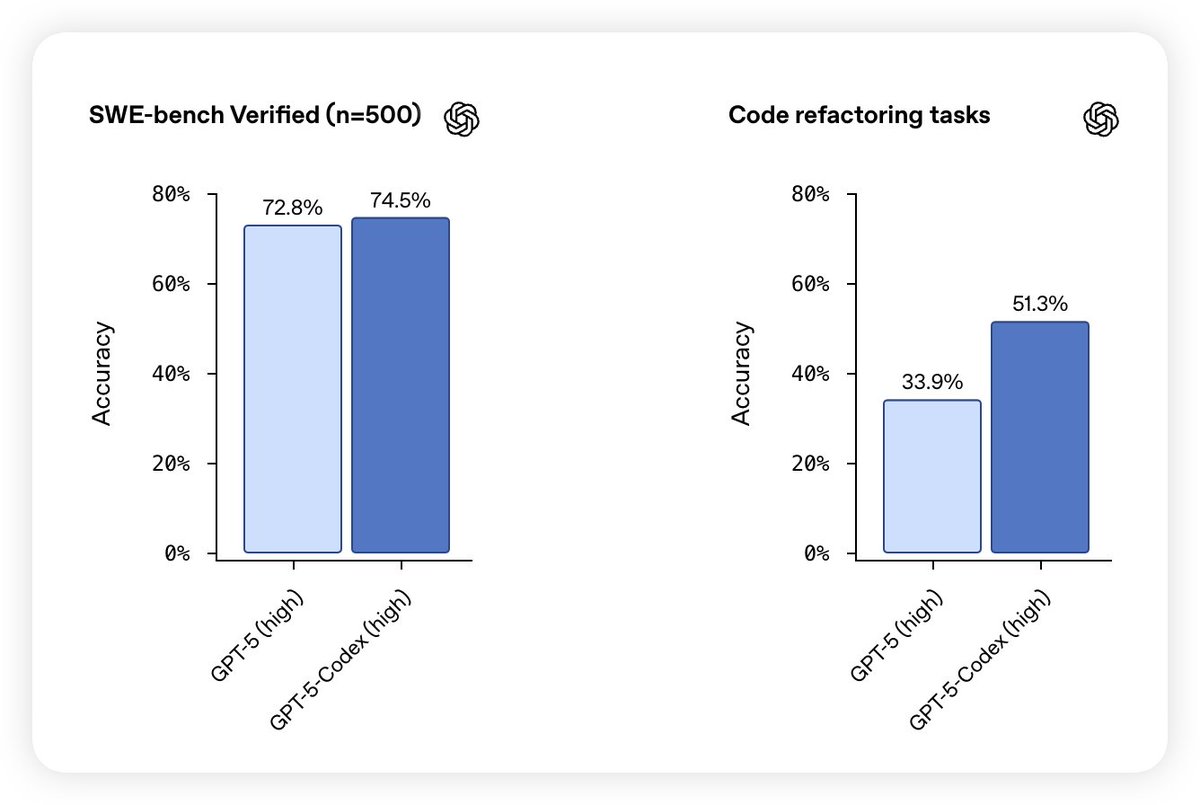
AI Agent在药物警戒领域的应用调研
AI Agent在药物警戒中的主要应用场景
药物警戒(Pharmacovigilance,PV)涉及对药品不良事件进行监测和处理,以保障用药安全。随着数据量激增和信息来源日益多样,传统人工方法难以及时、高效地应对。人工智能代理(AI Agent)通过自动化和智能分析正在帮助提升药物警戒的效率和准确性[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=Results AI has greatl y,detection%2C surveillance%2C and ADR reporting)[ema.europa.eu](https://www.ema.europa.eu/en/news/reflection-paper-use-artificial-intelligence-lifecycle-medicines#:~:text=At the marketing,report management and signal detection)。其主要应用场景包括:
- 不良事件报告收集与处理: AI可以辅助自动接收各渠道的不良事件/不良反应报告(如患者来函、医疗记录、呼叫中心记录等),进行信息抽取和个例报告(ICSR)初步录入与有效性核查。例如,光学字符识别(OCR)结合自然语言处理(NLP)技术可从扫描件、邮件中提取病例字段并录入数据库,机器人流程自动化(RPA)可完成表单填写和提交,将原需人工数小时的病例录入压缩至数分钟内完成[bestpractice.ai](https://www.bestpractice.ai/ai-case-study-best-practice/bayer_aims_to_spot_drug-associated_side_effects_earlier_with_the_use_of_machine_learning%2C_rpa_and_natural_language_processing_#:~:text=Bayer has partnered with Genpact,language processing%2C and machine learning)[highondata.com](https://highondata.com/posts/how-ai-is-shaking-up-pharmacovigilance/#:~:text=Most of the real AI,ago%2C who would’ve imagined that)。自动化病例处理不仅提高速度,也减少人工错误,并确保重要报告在法规时限内提交。
- 医学文献和社交媒体监测: 针对法规要求的文献监测,AI Agent可每天自动扫描海量期刊文献,识别其中记载的药品不良反应个案报告或安全性信号,减少人工逐篇阅读负担[highondata.com](https://highondata.com/posts/how-ai-is-shaking-up-pharmacovigilance/#:~:text=Most of the real AI,ago%2C who would’ve imagined that)。基于NLP的模型能“阅读”文章标题和摘要,判断是否包含特定药物的不良事件描述,从而筛选出需人工复核的文献清单。同样地,在社交媒体和患者论坛中,AI能够以文本挖掘技术捕捉患者对药品副作用的讨论,包括拼写错误或俚语表述,扩展不良反应信息来源[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=drugs to adverse events mentioned,PV often employs deep learning)[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=,NLP also)。这些工具提高了监测广度,并过滤掉大量无关信息,让安全专家将精力集中于相关线索。
- 安全信号检测与信号管理: AI算法可以从大型不良事件数据库中挖掘出异常模式或关联,辅助检测新的安全信号。传统信号检测依赖比值信号算法等,而机器学习模型(如集成方法或深度学习)能够综合多维数据,提高信号检出灵敏度。例如,AI可聚类分析病例报告,发现罕见模式;或结合多个数据源实时监测,用早期发现潜在风险信号[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=Results AI has greatl y,detection%2C surveillance%2C and ADR reporting)[ema.europa.eu](https://www.ema.europa.eu/en/news/reflection-paper-use-artificial-intelligence-lifecycle-medicines#:~:text=At the marketing,report management and signal detection)。有报告指出,应用数据挖掘和自动信号识别技术可以将安全信号发现速度大幅加快[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=Results AI has greatl y,detection%2C surveillance%2C and ADR reporting)。某些先进系统还能整合自发报告、电子健康记录等数据,实现更全面的信号管理,并对每个信号进行优先级排序和趋势分析。此外,WHO药物监测中心开发的vigiRank算法就是利用机器学习对全球不良反应数据库(VigiBase)中的信号进行优先排序的一种实践。
- 自动化报告和撰写: AI Agent还能辅助撰写各类药物警戒报告。例如,基于生成式AI的大语言模型可用于起草不良反应叙述、病例摘要,或定期安全性更新报告(PSUR/PBRER)的初稿。通过“阅读”案例数据和既往报告,AI可以生成规范的文本草案,供安全专家审核修改,从而节省大量撰写时间[highondata.com](https://highondata.com/posts/how-ai-is-shaking-up-pharmacovigilance/#:~:text=1,14 Bayer’s already doing)。业内已展望AI自动生成高质量的病例叙述和汇总分析,例如根据实验室数据和文献自动编写完整的不良事件叙述。再比如智能编码方面,AI模型能够解析自由文本症状并建议匹配的MedDRA术语,提升不良事件术语编码的一致性和速度(据报道,拜耳公司已在尝试利用AI进行医学术语智能编码[highondata.com](https://highondata.com/posts/how-ai-is-shaking-up-pharmacovigilance/#:~:text=create summaries and draft reports—saving,rules or missing business configurations))。
- 其他应用: 除上述场景外,AI在药物警戒中还有一些特殊应用。例如利用模式识别进行重复病例检测,自动比对新的病例报告与数据库中已有报告,识别出内容高度相似的重复上报,从而净化数据(研究显示这提高了安全评估的数据准确性[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=xpedited safety signal identification%2C while))。又如因果关系评估,传统上个例因果关系判断依赖人工且主观,现有AI工具(如专家知识驱动的贝叶斯网络)可辅助评估报告中的药物与事件关联概率。在某地区药物警戒中心的试点中,引入贝叶斯网络模型将疑似不良反应因果评估的处理时间从数天缩短到数小时,降低了人为主观差异,提高了评估一致性[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=proactive patient care,defined Bayesian network)。此外,AI还用于预测性风险建模,例如根据历史数据训练模型预测哪些患者更可能发生特定不良反应,从而预先采取监测措施[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=xpedited safety signal identification%2C while)[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=deepening drug safety and efficacy,drug interactions%2C enabling)。总体而言,AI Agent正在贯穿个例报告收集、信号检测到报告撰写的各个药物警戒环节,充当人类的智能助手,大幅提升工作效率。
已落地的AI Agent药物警戒案例
近年来,多家制药企业、合同研究组织(CRO)和科技厂商在药物警戒领域部署了AI Agent解决方案并取得积极成果。下表汇总了一些典型的落地实践:
| 实施主体(单位) | AI应用场景与方案 | 实施效果及成效 |
|---|---|---|
| 拜耳(Bayer)与Genpact – 跨国制药企业与专业服务商合作 | 引入Genpact的药物警戒AI平台(PVAI),整合OCR、RPA、NLP和机器学习,实现不良事件病例从报告接收、信息提取到录入的端到端自动化处理[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=,Bayer’s collaboration aimed to) | POC测试表明,大部分病例处理步骤可由AI自动完成,显著减少人工工作量[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=Pharmacovigilance Artificial Intelligence ,learns as more cases flow);拜耳预计借此加速发现潜在药品安全性问题,释放人力专注于高级风险管控措施[bestpractice.ai](https://www.bestpractice.ai/ai-case-study-best-practice/bayer_aims_to_spot_drug-associated_side_effects_earlier_with_the_use_of_machine_learning%2C_rpa_and_natural_language_processing_#:~:text=Genpact asserted that its PVAI,undertaken by big pharmaceutical firms) |
| 赛诺菲(Sanofi)与IQVIA – 大型药企与CRO合作 | 启动“ARTEMIS”计划,采用IQVIA Vigilance平台实施PV流程数字化改造,目标是全流程自动化病例管理[iqvia.com](https://www.iqvia.com/library/articles/sanofi-revolutionizes-pharmacovigilance-with-project-artemis#:~:text=Sanofi's pharmacovigilance journey to fully,monitoring and adverse event reporting) | 实现病例收集、分类、评估和上报的一体化自动处理,大幅提升效率与一致性[iqvia.com](https://www.iqvia.com/library/articles/sanofi-revolutionizes-pharmacovigilance-with-project-artemis#:~:text=Sanofi's pharmacovigilance journey to fully,monitoring and adverse event reporting);被视为赛诺菲药物警戒模式的重要飞跃,有助于更及时地进行药品安全监测和报告[iqvia.com](https://www.iqvia.com/library/articles/sanofi-revolutionizes-pharmacovigilance-with-project-artemis#:~:text=Sanofi's pharmacovigilance journey to fully,monitoring and adverse event reporting) |
| 辉瑞(Pfizer) – 制药企业自主体验 | 进行AI病例处理工具可行性研究,一次性将同一批真实案例交由三家不同厂商的AI系统处理,对比提取关键字段和判断有效性的准确性[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=,a discovery phase for broader) | 结果证明AI可以可靠地从源文件中提取所需信息并判定病例是否满足报告标准,与人工结果高度一致[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=pmc,world PV use%2C given Pfizer’s)。辉瑞据此选定表现最佳的方案深入开发,表明业内对AI成熟度的信心提高 |
| 葛兰素史克(GSK) – 制药企业内部研发与合作 | 内部开发AI技术用于自动化案例处理,并与科技公司合作应用机器学习进行大型安全数据库分析[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=co,Such partnerships allow) | 据报道,GSK利用AI辅助个例处理和数据分析以优化其药物警戒流程[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=co,Such partnerships allow);还对外投资初创公司,共建AI工具,以提高全球PV运营的效率和洞察 |
| IQVIA Vigilance Detect – CRO提供的AI监测平台 | IQVIA开发的多数据源安全监测工具,应用于多家大型药企,自动分析自发报告、呼叫中心记录、患者支持项目和社交媒体等多渠道数据[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=,reducing noise for human) | 某项目中系统一年处理了数百万条非结构化安全数据,将社交媒体中的无关信息过滤减少了66%[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=support program data%2C social media%2C,party audit);通过语音转文本与NLP分析呼叫记录,将人工筛听工作量减少94%[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=non,form digital content under one);第三方审计显示,系统成功捕捉到以往人工遗漏的100%不良事件线索[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=non,form digital content under one) |
| ArisGlobal LifeSphere – 科技厂商信号管理解决方案 | ArisGlobal推出的新一代PV软件平台LifeSphere引入AI功能,用于安全信号检测和案例处理等。某大型药企部署了其Advanced Signals模块,利用机器学习模型对信号进行优先级排序和评估[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=Advanced Signals%2C an AI,time) | 部署后,安全专家的信号评估速度提高了80%,信号检测的误报率下降近一半,从而更高效地聚焦真实风险[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=Advanced Signals%2C an AI,time)。该系统还支持实时数据监测,使企业可以更早发现并应对潜在安全问题[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=benefits included an 80,media) |
| IBM Watson for Drug Safety – 人工智能平台应用 | IBM Watson健康部门曾开发认知计算服务用于药物警戒,大型药企Celgene曾合作利用Watson的AI能力分析海量不良事件报告和电子病历,以发现新的安全性信号[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=is using IBM Watson’s AI,While) | Watson能阅读医学自由文本,从数以百万计的报告中识别可能的安全隐患[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=is using IBM Watson’s AI,While);在案例分类和信号初筛方面表现出较高准确性,验证了“认知计算”用于PV的可行性。此实践推动了AI在PV中验证框架的讨论,IBM研究人员提出了验证AI算法性能的思路以满足法规质量标准[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=introducing the concept of “cognitive,meet quality thresholds similar to) |
上述案例表明,AI Agent已在药物警戒各环节取得积极进展:从自动化病例录入、智能信号检测,到报告撰写和决策支持均有成功实践。多数企业报告缩短了处理周期、降低了人工成本,并在一定程度上提高了信号发现的灵敏度和准确性。例如,拜耳采用AI后预期案例处理效率提升40-60%[bestpractice.ai](https://www.bestpractice.ai/ai-case-study-best-practice/bayer_aims_to_spot_drug-associated_side_effects_earlier_with_the_use_of_machine_learning%2C_rpa_and_natural_language_processing_#:~:text=Bayer has partnered with Genpact,language processing%2C and machine learning)[bestpractice.ai](https://www.bestpractice.ai/ai-case-study-best-practice/bayer_aims_to_spot_drug-associated_side_effects_earlier_with_the_use_of_machine_learning%2C_rpa_and_natural_language_processing_#:~:text=Genpact asserted that its PVAI,undertaken by big pharmaceutical firms),ArisGlobal客户通过AI信号检测将信号评估时间从数周减至几天[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=benefits included an 80,media)。尽管一些项目仍处于试点或早期阶段,但整体趋势显示AI正从概念验证走向实际生产部署,行业对其价值的认可度提高。不过,也有企业反映在全面落地时遇到数据质量、系统集成、监管合规等挑战,需要持续投入加以解决[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=network has optimized causality assessment%2C,hindered by data quality issues)。
药物警戒相关AI系统部署的监管法规
AI Agent在药物警戒领域的部署涉及到严格的医药监管要求,需要符合制药行业的GxP规范以及各国监管指南。以下从国际指南和主要监管机构政策出发,说明哪些原则或条款适用于药物警戒中的AI系统:
- GxP质量管理原则: 药物警戒活动属于受管制的药品安全领域,因而所有相关系统必须遵循GxP中对系统和数据的要求。其中尤以临床试验质量管理规范GCP(Good Clinical Practice)和药物警戒规范GVP(Good Pharmacovigilance Practice)为重。**ICH E6《临床试验质量管理规范》*明确要求,凡用于临床研究的数据处理的计算机化系统均需经过*充分的验证,以证明在设计至退役的全生命周期内系统能够符合预定要求[ema.europa.eu](https://www.ema.europa.eu/en/documents/scientific-guideline/ich-guideline-good-clinical-practice-e6r2-step-5-revision-2_en.pdf#:~:text=1,assessment that takes into consideration)。这意味着,无论AI用于临床试验期间的不良事件管理,还是用于上市后PV流程,均应按照GCP精神确保系统经过验证、准确可靠。ICH E6(R3)尽管未直接提及“人工智能”,但强调技术的使用应适配试验设计且不能降低对受试者权益的保护[fdaqrc.com](https://fdaqrc.com/project/ich-ai/#:~:text=FDAQRC’s Senior Project Manager%2C Randall,with the most relevant being)[fdaqrc.com](https://fdaqrc.com/project/ich-ai/#:~:text=Randall contends that ICH E6,Drug Administration’s Draft Guidance Document)。**ICH E19《选择性安全数据收集指南》**则针对特定情形下减少非关键安全数据收集提供了框架。虽该指南未直接涉及AI,但其倡导的**聚焦重要安全信息**的原则可由AI辅助实现——例如利用智能算法从海量真实世界数据中挑选出高价值的安全信息,从而优化数据收集策略。业界也提出应让AI工具遵循ICH E19所倡导的标准化方法,以在全球范围内协调信号检测程序[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=ration through shared AI platforms,and frameworks—f or)。
- 美国FDA法规和指南: 在美国,凡用于药物安全监管的数据系统需符合FDA的电子记录和签名法规(21 CFR Part 11),确保电子数据的可信任性和可追溯性(如权限控制、审计追踪等要求)。针对AI本身,FDA近年来积极介入制定指导方针。2023年CDER启动“新兴药物安全技术项目(EDSTP)”,旨在与业界就AI在药物警戒中的应用展开对话,分享验证经验并探讨监管标准highondata.com。2025年1月,FDA发布了AI在药物和生物制品监管决策中应用的指南草案[fda.gov](https://www.fda.gov/regulatory-information/search-fda-guidance-documents/considerations-use-artificial-intelligence-support-regulatory-decision-making-drug-and-biological#:~:text=Considerations for the Use of,Other Interested Parties January 2025)。《用于支撑监管决策的人用药品人工智能使用考虑(草案)》中提出了基于风险的AI模型可信度评估框架,要求申请人在将AI用于支持安全性或有效性决策时,明确模型的用途情境(Context of Use)并据此评估模型风险等级[fda.gov](https://www.fda.gov/regulatory-information/search-fda-guidance-documents/considerations-use-artificial-intelligence-support-regulatory-decision-making-drug-and-biological#:~:text=This guidance provides recommendations to,COU)。对于高风险用途的AI(例如直接影响安全决策的),应提供充分的模型验证证据和风险缓解措施。FDA草案指南还强调**模型可信度(credibility)**建立的重要性,包括数据选择、模型验证、性能表现、透明度等方面[fda.gov](https://www.fda.gov/regulatory-information/search-fda-guidance-documents/considerations-use-artificial-intelligence-support-regulatory-decision-making-drug-and-biological#:~:text=This guidance provides recommendations to,COU)。此外,如果AI系统处理的是上市后不良事件报告等安全数据,企业仍必须遵守既有药物警戒法规(如21 CFR 314.80关于持证商上报不良反应的要求等),AI的介入并不能降低报告的及时性和合规性义务。总的来说,FDA当前通过**指导原则而非强制法规**来引导AI在药物监管中的应用,并鼓励企业在实践中与监管机构充分沟通AI方案的验证和表现。
- 欧洲EMA政策与指南: 欧洲药品管理局(EMA)对于AI在药物领域的态度同样积极谨慎。2024年EMA发布了《关于在药品生命周期中使用人工智能的反思文件(Reflection Paper)》[fdaqrc.com](https://fdaqrc.com/project/ich-ai/#:~:text=Globally%2C industry professionals are beginning,GCP) states that)。该文件明确提出,在临床试验等情境中使用AI/ML必须满足ICH GCP的适用要求[fdaqrc.com](https://fdaqrc.com/project/ich-ai/#:~:text=Clinical trials%3B 2,GCP) states that);在上市后药物警戒中,若AI用于不良事件报告分类、严重程度评级或信号检测等,则应进行专门的风险评估和充分的文件记录,并确保符合药物警戒质量管理规范(GVP)的要求[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=datamatters,which runs the WHO)。EMA将涉及患者安全的AI系统视为高风险(high-risk)*工具,要求企业建立*严格的监管监督和透明机制[intuitionlabs.ai](https://intuitionlabs.ai/articles/ai-pharmacovigilance-drug-safety#:~:text=specifically calls out PV and,which runs the WHO)。这与欧盟《人工智能法案(EU AI Act)》中对高风险AI系统(包括医疗和药物安全领域)的分类是一致的[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=The EU AI Act%2C adopted,where the AI system significantly)。EU AI法案(2024年通过)采用分级监管,高风险AI需满足风险管理、透明度、数据治理和人为监督**等强制要求[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=The EU AI Act%2C adopted,where the AI system significantly)。虽然药物警戒AI系统具体归类需视其用途而定,但若AI直接影响患者安全或关键监管决策,通常会被视作高风险,必须有人类在环监督和完善的合规控制。EMA反思文件还倡导“以人为本”的AI开发部署原则,强调任何AI的应用都不能违背现行法律和伦理,对基本人权(如隐私)的尊重需得到保障[ema.europa.eu](https://www.ema.europa.eu/en/news/reflection-paper-use-artificial-intelligence-lifecycle-medicines#:~:text=The reflection paper highlights that,due respect of fundamental rights)。在实践层面,EMA建议公司在计划应用AI于药物开发或安全监测时,可以提早寻求监管科学建议或工具资格认定,以确保AI方法得到监管认可[ema.europa.eu](https://www.ema.europa.eu/en/news/reflection-paper-use-artificial-intelligence-lifecycle-medicines#:~:text=If an AI%2FML system is,or scientific advice)。
- 国际组织与行业指南: 除ICH、FDA、EMA外,国际药物监管合作组织也在积极制定AI治理准则。其中值得关注的是CIOMS(国际医学科学组织理事会)第十四工作组针对AI在药物警戒的指南草案(2025年发布征求意见稿)。该草案借鉴WHO、OECD以及各国原则,提出了安全负责的AI使用指导原则,涵盖风险管理、数据质量、偏见防范、人为监督、透明可解释、持续监测等方面[highondata.com](https://highondata.com/posts/how-ai-is-shaking-up-pharmacovigilance/#:~:text=2,Read more here)。CIOMS报告将欧盟AI法案的高阶要求细化为药物警戒可操作实践,并与EMA正在进行的监管科学战略相呼应[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=The Draft Report translates the,a goal the Draft Report)。例如,它建议在PV应用中进行AI系统影响的分级评估(判断是否高患者风险或高监管影响),并据此决定监督和验证深度[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=AI%2C using a risk,making)[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=regulatory efforts by the EMA%2C,legally compliant%2C scientifically robust%2C and)。CIOMS草案还强调,无论在有无专门立法的国家,企业都应主动参考这些国际最佳实践来完善内部AI治理。总体而言,当前尚无专门针对药物警戒AI的强制法规,但现行的GCP/GVP原则和数据完整性要求对AI系统同样适用,而EMA等机构的反思文件和CIOMS指南为行业提供了更明确的遵循框架。
合规前提下使用AI Agent的关键措施
为了在合规前提下应用AI Agent于药物警戒,企业需要采取一系列措施,确保AI系统可靠、安全、可解释并满足监管要求。关键措施包括:
- 系统验证与风险评估: 在部署AI之前,按照计算机化系统验证(CSV)要求对其进行全面验证。[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=3,practices and data sources evolve)建议建立基准测试集,用真实的药物警戒数据对AI模型进行定性和定量验证,确保其输出准确可靠。同时结合风险评估原则,根据AI用途情境和可能影响,确定验证深度和控制措施。对于高风险用途,需更严格的验证证据和更频繁的性能检查。验证不仅在初始部署时进行,还应包含持续性能监测,及时发现模型“漂移”或性能下降并纠正[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=3,practices and data sources evolve)。例如,定期重新评估AI在新数据集上的准确率,如发现偏差超出阈值应触发模型更新或调整。
- 模型透明性与可解释性: 确保AI决策过程对专业人员和监管机构而言是透明且可解释的。欧盟AI法案已将透明度作为高风险AI的核心要求[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=4,AI interaction)。为此,企业应做到:完整记录模型开发和训练过程,保留模型版本说明文档;明确模型预期输入输出及使用限制;对外部提供足够的信息说明AI在何处以何种方式参与了药物警戒流程[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=decision,generating or processing safety information)。技术上,可采用**可解释AI(XAI)**方法,提高模型输出的可理解性,例如提供影响判定的关键特征、决策规则示例等。[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=importance of keeping systems transparent,user trust%2C and error investigation)指出,应实现能够支持监管审计和错误调查的解释机制,以便在需要时,人类审评人员可以追溯分析AI给出的结论是如何产生的。透明可解释的AI有助于建立监管和公众信任,也是合规使用AI的基础。
- 数据完整性、可追溯性与审计追踪: AI系统所处理的安全数据必须符合数据完整性原则,即真实、准确、可追溯、不可篡改。为此,需要实施严格的审计追踪机制和版本控制。[cioms.ch](https://cioms.ch/wp-content/uploads/2022/05/CIOMS-WG-XIV_Draft-report-for-Public-Consultation_1May2025.pdf#:~:text=2459 Traceability and version control,impact patient safety or public)强调,在药物警戒这样关系患者安全的领域,必须详尽记录AI模型及数据处理过程的变更轨迹。例如,每版模型的源代码、训练数据集版本、性能指标都应存档备查[cioms.ch](https://cioms.ch/wp-content/uploads/2022/05/CIOMS-WG-XIV_Draft-report-for-Public-Consultation_1May2025.pdf#:~:text=match at L6955 2486 for,the source code for each)。当AI对病例数据进行增删改时,要有安全、计算机生成的时间戳审计日志记录操作人、时间、修改内容等,以符合21 CFR Part 11等法规要求。数据输入输出也需全程留痕,可回溯定位源头数据。当监管机构审计时,企业能够提供完整的证据链证明:数据从来源到AI处理再到报告的整个流程均保持完整一致,没有未经授权的更改。
- 人为监督与责任机制: 尽管AI可以高度自动化操作,但监管原则要求在关键节点保持**“人类在环”监督,明确人工对AI的监管责任[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=2,use cases are instructive for)。企业应制定清晰的治理架构和职责分配**,成立跨职能的AI治理委员会或工作组,对AI项目进行风险评估和持续监督[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=7,tools such as a governance)。根据不同应用场景,可以采用人参与(HITL)、人监控(HOTL)**或**人控管(HIC)*等模式:例如AI先自动执行初步任务,再由人工复核结果(人-in-the-loop);或AI全程运行但人实时监视其输出(人-on-the-loop);以及在重要决策前必须经人工最终批准(人-in-command)[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=2,use cases are instructive for)。这些监督模式应在SOP中固化,并定期检讨有效性。[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=recommends the establishment of cross,oversight and external regulatory inspection)建议建立*定期审核制度,审查AI系统的决策质量和合规情况。同时规定,当AI判断出现疑似偏差或异常时,人工有义务介入调查,必要时暂停AI使用。通过制度化的人机协作和问责机制,确保AI的应用始终在可控范围内,符合法规对**最终责任归属的要求(即持证企业对药物警戒结果负全责,而不能将责任推诿给AI)。
- 人员培训与能力建设: 有效使用AI的前提是相关人员具备足够的知识和技能。因此企业需对药物警戒和IT团队开展针对性的培训,让他们理解AI模型的功能、局限和输出解读方法。[researchgate.net](https://www.researchgate.net/publication/394123083_Artificial_intelligence_in_pharmacovigilance_a_narrative_review_and_practical_experience_with_an_expert-defined_Bayesian_network_tool#:~:text=training and education—including AI modules,in pharma)指出,应在药物警戒培训课程中加入AI模块,并通过用户友好的可视化仪表板等手段,辅助工作人员正确interpret AI结果。培训内容包括:AI基础原理、模型性能指标意义、常见错误类型以及遇到异常输出时的处置流程等。除了专业人员培训,还应培养跨学科人才,例如既懂AI又懂药物安全的复合型专家,在内部担任AI项目的“产品负责人”或监督员角色。通过持续的教育和演练,保证团队能够与AI工具有效协作,发挥AI长处的同时弥补其短板[highondata.com](https://highondata.com/posts/how-ai-is-shaking-up-pharmacovigilance/#:~:text=,Keep humans in the loop)。例如,案例处理人员在引入AI后应调整工作重点,从繁琐的数据录入转向审核AI提取的信息和处理结果,这需要相应的能力转变。此外,企业还应更新SOP和工作指南,纳入AI相关流程和操作规范,确保所有员工在统一框架下使用AI系统。
综上,AI Agent在药物警戒中的应用前景广阔,但其落地必须建立在合规和质量基础之上。通过以上措施,企业可以在验证充分、透明可控、人员赋能的前提下安全地引入AI,加速药物安全监测流程。同时,紧跟监管动向和最佳实践(如参与CIOMS指南反馈[datamatters.sidley.com](https://datamatters.sidley.com/2025/06/02/artificial-intelligence-in-pharmacovigilance-eight-action-items-for-life-sciences-companies/#:~:text=8,to the development of future)),不断改进AI治理策略。只有做到技术创新与合规要求并重,才能真正发挥AI提升药物警戒水平的潜力,既保障患者安全又推动行业进步。