第一部分:AI Agent在药物警戒生态系统中的兴起
本部分旨在为报告奠定基础,阐述AI Agent旨在解决的核心问题,并明确其在药物警戒(Pharmacovigilance, PV)领域的定义、范畴及应用。
第一章:以智能自动化重塑药物警戒
1.1 数据洪流与自动化势在必行
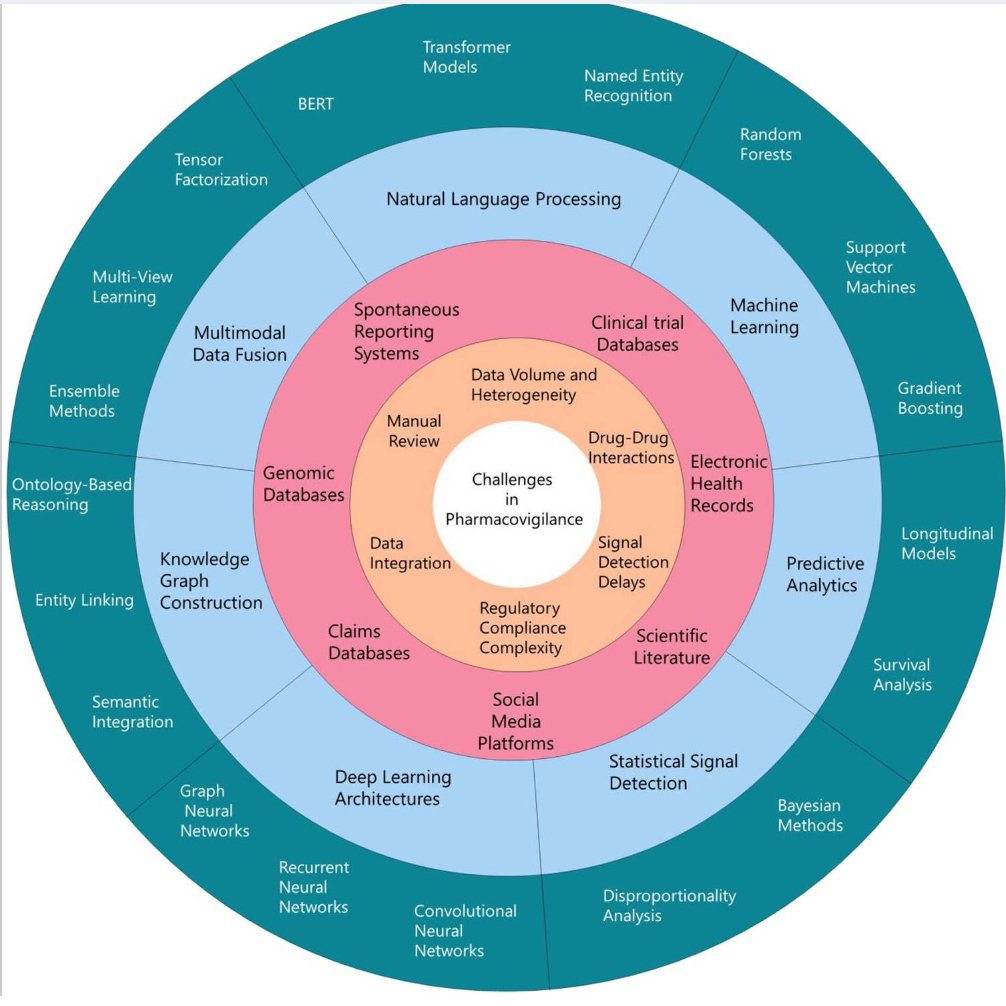
传统药物警戒体系正面临前所未有的挑战。不良事件(Adverse Event, AE)数据的数量和种类呈指数级增长,其来源日益多样化,涵盖了自发呈报、临床试验、电子健康记录(EHRs)以及社交媒体等多个渠道,这给数据处理带来了巨大的瓶颈 1。传统方法不仅存在报告不足的问题,而且在处理海量数据时效率低下,难以从庞杂的“噪音”中精准识别出真正的药物安全信号 1。这种运营压力使得药物警戒部门常常被视为成本中心,从而推动整个行业积极寻求自动化解决方案,以应对规模化处理的需求并控制成本 2。
随着每年不良事件案例量以10%至15%的速度增长,药物警戒预算的很大一部分被消耗在案例接收和处理等事务性工作上 2。因此,平台现代化的首要目标通常是利用机器人流程自动化(RPA)等技术来自动化这些流程,从而降低成本并提高效率。人工智能(AI)模型的引入,通过加速不良反应报告的处理、提高安全信号的准确性,并利用非结构化数据进行及时报告,克服了传统方法固有的局限性 3。这一技术变革旨在将PV部门从一个被动的成本中心,转变为一个能够为业务增加价值的战略部门,通过主动识别风险来保障患者安全,从而减少不必要的医疗成本并提升整体运营效率 3。
1.2 AI Agent在药物警戒领域的定义
在药物警戒的语境下,对“AI Agent”进行精准定义至关重要,因为它并非一个单一的概念,而是涵盖了从简单自动化到高级自主决策的一系列能力。
核心定义
AI Agent是一种能够感知其环境、做出决策并采取自主行动以实现特定目标的软件系统 7。它们综合运用了机器学习(ML)、自然语言处理(NLP)和大型语言模型(LLM)等先进技术,以自主方式行动并实时调整其行为 3。这些智能系统能够处理和分析海量的患者数据、临床信息和医疗记录,通过先进算法识别模式和趋势,从而实现主动而非被动的响应,能够预测需求、识别模式并推动医疗创新 7。
AI Agent分类学
对AI Agent进行分类是评估其监管风险和验证要求的基础。根据其复杂性和自主性,可将其分为以下几类:
- 简单反射/基于规则的Agent (Simple Reflex / Rule-Based Agents): 此类Agent根据预定义的规则集执行简单的、重复性的任务,例如自动化数据录入或根据特定关键词对报告进行初步分类 8。它们不考虑历史经验或未来后果,适应性较差。
- 反应型与基于目标的Agent (Reactive and Goal-Based Agents): 反应型Agent仅根据当前感知进行操作,而基于目标的Agent则为实现特定目标而设计,同时会考虑潜在的障碍 7。在PV中,一个基于目标的Agent可能会被设定为“在15天内提交所有严重不良事件报告”,并自主协调所需步骤。
- 学习型Agent (Learning Agents): 这类Agent利用机器学习技术,通过经验不断学习和改进其性能 7。例如,一个学习型Agent可以通过分析历史案例处理数据,逐步提高其对不良事件术语进行MedDRA编码的准确性。
- 专业垂直领域Agent (Specialized Vertical Agents): 这类Agent专为特定行业或功能而设计。在药物警戒领域,典型的例子包括:
- 语音Agent (Voice Agents): 专用于处理药物安全电话和语音交互的AI对话系统,能够以符合合规要求的准确性捕获不良事件、产品投诉和医学信息咨询。它们可以自动引导来电者完成标准问卷,并将结构化数据传输至安全数据库 10。
- 药物警戒Agent (Pharmacovigilance Agents): 通过分析公共论坛、社交媒体和健康报告等实时数据,追踪患者的用药体验,主动监测和发现不良药物事件(ADEs),并立即向医疗保健提供者发出警报 7。
- 生成式AI / LLM驱动的Agent (Generative AI / LLM-Powered Agents): 这是目前最先进的类别,具备上下文感知推理、复杂问题解决和生成类人文本的能力 3。在PV领域,这类Agent不仅能从非结构化文本中提取信息,还能自动生成符合监管要求的个例安全性报告(ICSR)叙述部分或定期报告草案。
将“AI Agent”理解为一个从简单到复杂的连续谱系,是制定合规策略的逻辑起点。一个简单的、基于规则的自动化工具与一个能够自主学习和生成报告的LLM驱动Agent,其潜在风险截然不同。监管机构,尤其是美国食品药品监督管理局(FDA)和欧洲药品管理局(EMA),其监管框架本质上是基于风险的 11。系统的风险水平取决于其对患者安全和监管决策的潜在影响,以及人类对其控制的程度。因此,企业在部署任何AI Agent之前,首要且最关键的战略步骤是精确地对其进行分类。这个分类将直接决定后续的整个合规路径——从验证计划的严谨程度到人类监督模型的设计。如果将一个复杂的学习型Agent错误地归类为简单的自动化工具,可能会导致严重的合规失败。
1.3 贯穿药物警戒生命周期的核心应用
AI Agent的能力可以映射到药物警戒工作流程中多个关键且影响深远的环节,从而实现端到端的效率提升和质量改进。
案例接收与处理 (Case Intake and Processing)
这是AI Agent应用最成熟的领域之一。它们能够自动化处理来自邮件、传真、电话记录等非结构化和半结构化源文件中的不良事件数据 10。具体应用包括:
- 信息提取与数据录入: 利用NLP和光学字符识别(OCR)技术,自动从源文件中提取关键信息(如患者信息、药品、不良事件描述),并填入安全数据库的相应字段 1。
- 医学编码: 自动将报告中的症状和药品名称与MedDRA(国际医学用语词典)和WHODrug(世界卫生组织药物词典)等标准术语进行匹配和编码,提高了一致性和准确性 10。
- 重复检测与有效性评估: 通过比对案例信息,自动识别重复报告,并根据是否满足最低有效性标准(可识别的报告者、患者、药品和不良事件)进行初步评估 1。
不良事件检测与信号管理 (Adverse Event Detection and Signal Management)
AI Agent能够分析传统方法无法企及的海量、多样化数据集,从而更早、更准确地发现潜在的安全信号。
- 多源数据监控: 持续分析来自EHRs、社交媒体、医学文献和公共论坛的数据,以实时识别传统报告系统可能遗漏的潜在安全问题 7。
- 模式识别: 利用机器学习算法,在庞大的数据集中发现药物与不良事件之间隐藏的、复杂的关联模式,以及潜在的药物-药物相互作用 17。这有助于区分真实的药物安全信号和随机的“噪音” 3。
风险评估与管理 (Risk Assessment and Management)
AI Agent的应用使药物警戒从被动响应转向主动预防。
- 预测性分析: 通过分析历史数据,构建预测模型,以识别具有较高不良药物反应(ADR)风险的患者群体,从而实现前瞻性干预 3。
- 个性化医疗: 结合患者的基因组学信息、病史和当前健康状况,AI算法可以辅助制定个性化的用药方案,以优化疗效并降低副作用风险,这反映了向精准医疗的转变 15。
监管报告与合规 (Regulatory Reporting and Compliance)
AI Agent能够显著提升监管报告的效率和质量。
- 报告生成自动化: 自动生成ICSR的叙述部分,甚至起草定期安全性更新报告(PSURs)等汇总报告的初稿,确保内容的标准化和一致性 1。
- 合规性监控: 自动追踪和管理全球各地的报告时限,确保所有案例都能按时提交,从而降低合规风险 20。
第二部分:全球监管与GxP合规格局
本部分深入分析全球三大主要药品监管机构的监管框架,并探讨如何将基础的GxP(良好实践)原则应用于AI系统的管理。
第二章:解读美国FDA的药物安全AI框架
2.1 FDA的前瞻性立场
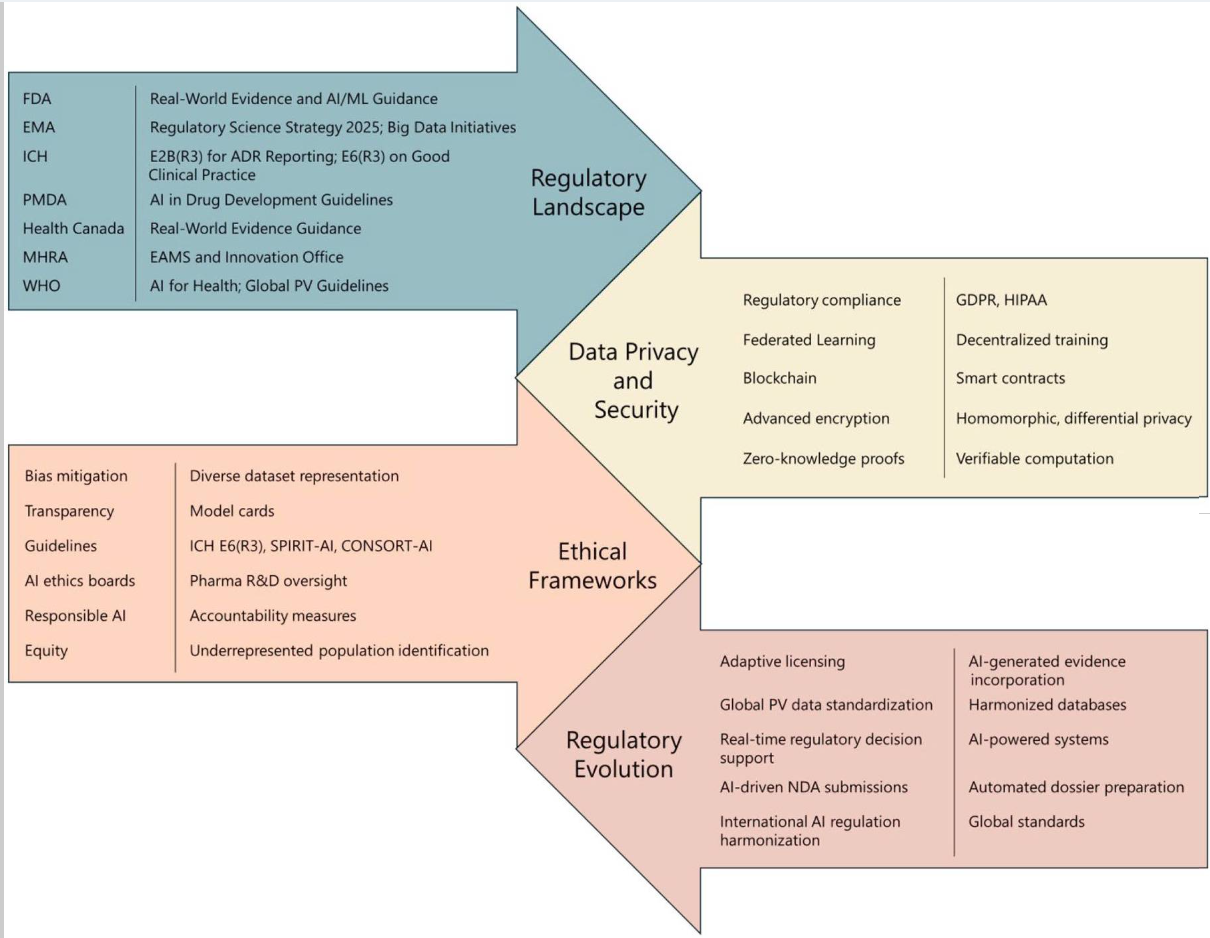
美国食品药品监督管理局(FDA)已明确认识到AI/ML技术在药品全生命周期中应用的显著增长,并正积极构建一个基于风险的监管框架,旨在鼓励创新的同时,坚定地保障患者安全 21。这标志着FDA的监管策略正从对新技术的被动反应,转向主动引导和合作。FDA致力于确保药物的安全性和有效性,同时促进药物开发的创新,并计划继续发展和采用基于风险的监管框架,以平衡创新与患者安全 21。
2.2 解构《支持药品和生物制品监管决策的人工智能使用考量》指南草案
这份于2025年1月发布的指南草案是理解FDA对AI监管思路的基石文件 11。它并未提出一套僵化的规则,而是提供了一个灵活且严谨的框架,用于评估AI模型输出结果的可靠性。
基于风险的7步可信度评估框架
该框架是指南的核心,旨在为特定使用场景(Context of Use, COU)建立和评估AI模型的可信度,其严谨程度与模型风险相称 11。
- 定义利益问题 (Define the Question of Interest): 清晰、准确地阐述AI模型旨在解决的具体问题、辅助的决策或关注点。例如,在临床开发中,问题可能是:“哪些受试者在服用A药物后可被视为低风险,无需进行24小时住院监测?” 11。
- 定义使用场景 (Define the Context of Use - COU): 详细描述AI模型在解决上述问题时所扮演的具体角色和范围。这包括模型将如何使用其输出,以及是否会与其他证据(如临床研究数据)结合使用 11。
- 评估AI模型风险 (Assess AI Model Risk): 这是框架的关键。模型风险并非指模型本身的技术风险,而是指其输出可能导致错误决策并引发不良后果的可能性。该风险由两个核心因素共同决定 11:
- 模型影响力 (Model Influence): AI模型提供的证据相对于其他所有证据的贡献度。如果AI是决策的唯一依据,则其影响力为高。
- 决策后果 (Decision Consequence): 因错误决策而导致的不良后果的严重性。如果错误决策可能导致危及生命的事件,则决策后果为高。
- 制定可信度评估计划 (Develop a Credibility Assessment Plan): 根据已确定的利益问题、使用场景和模型风险,制定一份详细的计划。该计划需包含对模型、数据、训练过程和评估方法的全面描述,其详尽程度应与模型风险成正比 11。
- 执行计划 (Execute the Plan): 按照既定计划开展所有可信度评估活动 11。
- 记录结果与偏差 (Document Results and Deviations): 将所有评估结果、发现以及与原计划的任何偏差,系统地记录在一份全面的可信度评估报告中 11。
- 确定模型对COU的充分性 (Determine Adequacy for COU): 基于评估报告,最终判断该AI模型是否适合其预设的使用场景。如果可信度不足,可能需要降低模型影响力、增加评估的严谨性或拒绝该使用场景 11。
2.3 新兴药品安全技术计划(EDSTP)的角色
EDSTP是FDA专门为促进业界与CDER(药品审评与研究中心)之间就AI及其他新兴技术在药物警戒中的应用进行对话而设立的正式渠道 25。该计划旨在通过新兴药品安全技术会议(EDSTMs),加深FDA对行业内AI用例、相关风险与收益、模型评估流程的理解,从而为未来监管政策的制定提供信息 26。这体现了FDA鼓励早期沟通与合作的监管理念,为企业在正式提交申请前获得反馈提供了宝贵机会。
2.4 全生命周期维护与持续监控
FDA的指南草案特别强调了AI模型的动态特性。与传统软件不同,AI模型的性能可能会随时间推移或部署环境的变化而发生“漂移” 27。因此,指南要求申办方实施一个基于风险的生命周期维护计划,以主动管理模型的变更,确保持续的可靠性,这在GMP(药品生产质量管理规范)等GxP环境中尤为重要 11。该计划应包括性能监控指标、监控频率和重新测试的触发条件。任何可能影响模型性能的重大变更,都可能需要重新执行部分可信度评估流程 23。
第三章:欧洲药品管理局(EMA)的AI治理方法
3.1 EMA关于AI的立场文件
欧洲药品管理局(EMA)于2024年9月发布的《关于在药品生命周期中使用人工智能的立场文件》(Reflection paper on the use of AI in the medicinal product lifecycle)是其监管思路的核心体现 28。该文件不提供硬性规定,而是阐述了一套指导原则,旨在平衡AI带来的机遇与风险,确保其应用能够安全有效地推进药物开发和监管 12。
3.2 以人为本和基于风险的理念
EMA的监管哲学根植于两个核心支柱,这决定了其对AI治理的整体方法:
以人为本的方法 (Human-Centric Approach): EMA强调,AI应作为增强人类专家能力的工具,而非取代他们。这意味着必须建立强有力的人类监督机制 28。无论AI系统多么先进,药品上市许可持有人(Marketing Authorisation Holder, MAH)始终对药物警戒体系的完整性以及药品的获益-风险平衡负有最终和全部责任 31。这一责任不可转嫁给AI模型或其开发者。
基于风险的分类 (Risk-Based Categorization): 为了避免与《欧盟人工智能法案》中宽泛的“高风险”定义混淆,EMA提出了更具体、更贴合药品监管场景的风险类别 28:
“高患者风险” (high patient risk): 指AI工具的应用直接影响患者安全的情况。
“高监管影响” (high regulatory impact): 指AI工具的输出对监管决策(如批准上市、标签变更)有重大影响的情况。
监管审查的深度和所需的验证严格程度将根据AI应用落入哪个类别而定。例如,一个用于内部流程优化、风险较低的AI工具,其监管要求会远低于一个用于预测患者对治疗反应并直接影响临床决策的AI模型 32。
3.3 GxP合规是基石
立场文件明确指出,在药品生命周期中使用的任何AI/ML系统都必须符合现行的GxP标准 29。对于药物警戒而言,这意味着AI相关的操作和流程必须被整合到药物警戒体系主文件(Pharmacovigilance System Master File, PSMF)中,并遵循GVP(药物警戒质量管理规范)的原则 12。MAH有责任在其PV体系内对AI模型的性能进行验证、监控和记录,以减轻所有算法和模型带来的风险 12。
3.4 与更广泛欧盟立法的相互作用
EMA的指导并非孤立存在,它必须在欧盟更广泛的法律框架内进行解读和实施。这主要涉及两部关键法规:
- 《欧盟人工智能法案》 (EU AI Act): 该法案为AI系统提供了横向的法律框架,将某些应用(如用于医疗诊断的AI)归类为“高风险”,并对其提出了严格的要求,包括风险管理、数据治理、透明度和人类监督 28。
- 《通用数据保护条例》 (GDPR): 作为全球最严格的数据隐私法规之一,GDPR对处理个人健康数据提出了严格要求,包括处理的合法性基础、数据最小化原则、设计隐私保护以及保障数据主体的权利(如访问权、被遗忘权和获得解释的权利)10。在药物警戒中使用AI处理患者报告时,必须严格遵守GDPR的规定。
第四章:解读中国NMPA对药物创新与AI的立场
4.1 一个初生但不断演进的格局
与FDA和EMA已经发布了相对明确的指导文件不同,中国国家药品监督管理局(NMPA)尚未针对AI在药物开发或药物警戒领域的应用发布具体、详细的指南 35。中国的监管环境目前仍处于早期探索阶段,但其发展方向和监管理念已初见端倪 35。全球各地的监管机构,包括中国,都在积极探索利用AI技术来提高工作效率,加速药品审评审批流程 35。
4.2 从医疗器械框架中借鉴经验
目前,NMPA在AI领域最相关的监管实践来自于医疗器械行业,这为其未来在药品领域的监管策略提供了重要参考。诸如2022年发布的《人工智能医疗器械注册审查指导原则》等文件,为AI软件建立了一个基于规则的框架 36。该框架的核心特点包括:
基于安全级别的分类: 根据产品的预期用途、使用场景和核心功能,将AI医疗器械软件的安全级别分为轻微、中度和严重三个等级,并对应不同的监管要求 37。
强调数据质量和全生命周期管理: 指导原则对数据标注、算法性能评估、产品召回要求等进行了全面规定,强调了对AI医疗器械整个生命周期的质量控制 37。
与欧美更侧重于原则和标准的监管方式相比,NMPA在AI医疗器械领域的做法显示出一种更具规范性、更偏向于规则导向的趋势 38。
4.3 政策信号:鼓励创新与标准化并行
近期NMPA发布的多项政策文件,如《关于进一步深化审评审批制度改革鼓励药品医疗器械创新的意见》的相关落实文件中,明确表达了对研发创新的支持,并强调了为新技术建立标准的重要性 39。特别是文件中提到要“研究建立人工智能、医用机器人等前沿医疗器械标准化技术组织”,这清晰地表明了NMPA的战略方向——通过制定明确、可执行的技术标准来规范和引导AI等前沿技术的应用 39。
4.4 主要挑战与考量
在中国监管环境下应用AI面临的主要挑战是缺乏针对性的标准以及数据质量和数据碎片化问题 35。尽管政策层面鼓励创新,但由于缺乏成熟、细致的AI在药物警戒领域的监管路径,企业在华运营时必须在一个充满机遇但确定性较低的环境中前行。数据质量、技术局限性、人才短缺和标准缺失是全球监管机构在应用AI时面临的共同挑战,在中国尤为突出 35。
全球三大监管机构在AI治理上展现出一种有趣的模式:在核心理念上趋于一致,但在具体执行框架和监管成熟度上存在显著差异。这种“殊途同归”的现象为跨国制药企业带来了复杂的合规挑战。FDA提供了一个详尽的、以流程为导向的7步框架,要求企业“展示其工作过程” 11。EMA则提供了一套以原则为基础的指南,要求企业“证明其合理性” 12。而NMPA则正朝着一个以标准为核心的体系发展,未来可能要求企业“遵守其技术规范” 36。
尽管方法不同,但风险评估和患者安全始终是共同的焦点。然而,证明合规所需的证据形式却大相径庭。这意味着,一家全球性企业不能简单地创建一套通用的AI验证文件包来应对所有监管机构。正确的策略是开发一个模块化、可适配的全球治理框架。该框架的核心必须基于通用的GxP原则(如第五章所述),但其产出的证据文件必须能够根据不同监管机构的具体要求进行定制。例如,向FDA提交时,产出物应是遵循7步框架的可信度评估报告;而向EMA提交时,则应是论证系统如何满足其立场文件原则和GVP要求的说明文件。这种“一次转化,多次报告”的策略,对于实现全球运营效率和合规性至关重要。
表2.1:全球药物警戒领域AI监管框架对比分析
| 特征 |
美国食品药品监督管理局 (FDA) |
欧洲药品管理局 (EMA) |
中国国家药品监督管理局 (NMPA) |
| 指导文件/法规 |
《支持药品和生物制品监管决策的人工智能使用考量》指南草案 11 |
《关于在药品生命周期中使用人工智能的立场文件》28 |
尚无药品专项指南,参考《人工智能医疗器械注册审查指导原则》36 |
| 核心监管理念 |
基于风险,促进创新与保障患者安全并重 21 |
以人为本,基于风险,与现有GxP框架整合 28 |
鼓励创新,强调标准化和规则导向 39 |
| 关键框架 |
7步风险为本的可信度评估框架 11 |
基于原则的指导,强调MAH责任 31 |
基于安全级别的分类和技术审查要求(借鉴自医疗器械)37 |
| 风险分类方法 |
模型影响力 (Model Influence) + 决策后果 (Decision Consequence) 11 |
高患者风险 (High patient risk) + 高监管影响 (High regulatory impact) 28 |
轻微、中度、严重(借鉴自医疗器械软件安全级别)37 |
| 人类监督立场 |
强调“人在环路中”作为风险缓解措施,并影响模型影响力评估 11 |
“以人为本”是核心原则,要求强有力的人类监督 28 |
强调医生不能被AI取代,需人类最终决策(借鉴自医疗服务)37 |
| 验证与生命周期管理 |
要求详细的可信度评估计划和报告,并强调生命周期维护计划以应对模型漂移 11 |
要求MAH在其PV体系内验证、监控和记录模型性能,与GVP整合 12 |
强调全生命周期质量控制,包括技术评估和不良事件监测 37 |
| 数据治理与隐私链接 |
需符合HIPAA等法规;指南强调数据“适用性”(相关且可靠)11 |
必须与GDPR和《欧盟人工智能法案》保持一致 28 |
强调数据隐私、数据安全和真实世界数据应用的标准 40 |
第五章:在AI驱动的系统中坚持良好临床实践(GCP)
5.1 将核心GCP原则转化为AI语境
良好临床实践(GCP)是确保临床试验伦理和数据可信度的国际标准 41。当AI系统被用于临床试验的安全监测时,必须将GCP的核心原则延伸至这些技术系统。
- 受试者的权益、安全和福祉 (Rights, Safety, and Well-being of Subjects): 这是GCP的首要原则。AI系统必须经过严格验证,以确保它们不会因错过安全信号或产生错误警报而给患者带来风险 42。在涉及前瞻性同意的研究中,如果使用AI,应告知受试者,以便他们做出知情的参与决定 45。
- 数据完整性与可信度 (ALCOA+): GCP要求所有数据都应遵循ALCOA+原则,即数据应是可归因的(Attributable)、清晰的(Legible)、同期的(Contemporaneous)、原始的(Original)、准确的(Accurate),并且是完整的(Complete)、一致的(Consistent)、持久的(Enduring)和可用的(Available)46。对于AI系统,这意味着其决策过程必须有清晰、不可篡改的审计追踪,能够追溯到其所依据的原始数据和算法版本。
- 方案合规性与科学合理性 (Protocol Compliance and Scientific Soundness): AI模型的使用,包括其具体架构、参数、训练数据集和验证计划,都应在试验方案或相关文件中进行清晰、详细的描述,并提交给机构审查委员会(IRB)/独立伦理委员会(IEC)进行审查和批准 42。
- 合格的人员与明确的职责 (Qualified Personnel and Defined Responsibilities): 必须明确界定与AI系统互动或监督其运行的各类人员的职责,包括数据科学家、药物警戒专家、临床医生和质量保证人员。每个人都应具备执行其任务所需的教育、培训和经验 42。
5.2 ICH E6 (R3) 与技术赋能的临床试验
国际人用药品注册技术协调会(ICH)的GCP指南最新修订版(E6 R3)旨在提供更大的灵活性,以适应包括数字健康技术在内的创新试验设计和方法 44。这为AI的应用提供了支持性的监管框架,但同时也强调了对验证和质量管理采取与风险相称的方法的必要性。该指南鼓励对试验的各个方面进行深思熟虑的规划,以应对个体临床试验的特定和独特之处 44。
5.3 审计与核查准备
监管机构已明确表示,AI系统将成为GCP核查的一部分。EMA的立场文件指出,在GCP核查期间,监管机构可能会要求提供AI模型的完整架构、开发日志、验证和测试记录以及训练数据 12。这一要求将AI系统的文档管理提升到了与传统临床试验记录同等重要的地位。因此,AI系统必须从设计之初就具备透明性和可审计性,以确保在监管审查时能够提供充分的证据。
监管机构在制定AI合规要求时,并非从零开始,而是在很大程度上将现有的GxP原则扩展应用于这项新技术。这一观察对于企业实施AI具有深远的指导意义。EMA明确地将AI的使用与GxP标准和PSMF联系起来 12;FDA对数据质量、验证和生命周期管理的关注,与传统的计算机化系统验证(CSV)原则一脉相承 23;而将GCP的ALCOA+原则应用于AI生成的数据,则确保了其完整性和可审计性 46。
这对企业的启示是:AI的合规工作不应被孤立在IT或数据科学部门,而必须由质量与合规部门主导。构建AI治理框架的起点应该是企业现有的质量管理体系(QMS)。企业应当做的是调整和扩展其现有的关于CSV、数据完整性和风险管理的标准操作程序(SOPs),以应对AI的独有特性(如模型漂移和算法偏倚),而不是试图创建一个全新的、独立的合规体系。这种方法能够利用组织内已有的专业知识、文化和流程,从而使AI的采纳过程更迅速、更稳健。
第三部分:行业采纳与真实世界实施
本部分从理论转向实践,考察领先的制药公司和技术供应商如何应用AI Agent,以及他们正在取得的成果。
第六章:AI驱动的案例处理与接收自动化案例研究
6.1 拜耳与Genpact的PVAI合作
拜耳与Genpact的合作是行业内一个标志性的案例。该合作旨在利用Genpact的药物警戒人工智能(PVAI)解决方案,自动化处理来自非结构化和半结构化源文件的不良事件数据 13。该解决方案整合了OCR、RPA、NLP和ML技术,其核心目标是更迅速地识别安全问题,并将宝贵的人力资源解放出来,专注于风险最小化等更高价值的活动,同时保持高质量和合规性 49。尽管具体的量化成果(如效率提升百分比)并未公开披露,但这一合作本身就表明,一家全球领先的制药公司正在对AI在药物警戒效率提升方面进行重大的战略投资 13。
6.2 IQVIA的Vigilance平台
IQVIA提供了一个全面的软件即服务(SaaS)平台,旨在实现“无接触式”的案例处理 53。该平台利用AI技术自动化案例接收、验证、重复检查、信息脱敏和编码等多个环节 55。IQVIA的数据显示,其平台每年使用人工智能处理超过80万个安全案例,并翻译1.3亿单词,这证明了其解决方案的可扩展性 53。在一个与南非疫苗公司Biovac的合作案例中,该平台帮助其从劳动密集型的纸质系统成功过渡到符合现代监管标准的数字化解决方案,从而在精简的团队配置下有效管理大量工作 54。IQVIA的一项内部数据分析还揭示,在手动处理的案例中,高达50%的案例其结构化数据与非结构化叙述不匹配,这凸显了自动化在提升数据质量方面的巨大潜力 55。
6.3 辉瑞的试点项目
辉瑞的方法展示了企业在全面部署前如何进行审慎的评估。该公司与三家供应商合作开展了一项试点项目,测试ML/NLP系统从源文件(如医学叙述和实验室报告)中提取数据并填充至安全数据库的能力 14。测试结果表明,AI系统在捕获案例细节和评估案例有效性方面表现出“有希望的准确性”,从而验证了这些技术在实际应用中的可行性 14。
6.4 其他行业参与者与解决方案
药物警戒自动化市场正在迅速增长。除了上述案例,ArisGlobal的LifeSphere平台、IBM Watson健康解决方案以及Tech Mahindra等公司也纷纷进入该领域,提供旨在自动化PV工作流程不同环节的解决方案 9。例如,Tech Mahindra于2025年3月发布了由Nvidia AI软件驱动的自主药物警戒解决方案,利用代理式AI和自动化来提高PV流程的速度、准确性和效率 9。
第七章:利用AI加强信号检测与风险管理
7.1 从自动化到智能化的飞跃
如果说案例处理的自动化主要关注运营效率,那么AI在药物警戒领域的真正变革性潜力则在于增强其科学核心——信号检测与风险管理 56。与传统统计方法相比,AI模型能够从海量、高维度的数据中发现隐藏的模式和复杂的非线性关系,从而实现更早期、更精准的安全信号检测 18。
7.2 基于多样化数据源的主动监测
AI Agent能够超越传统的自发呈报系统,对更广泛的非结构化数据源进行持续监控,从而构建一个更全面的药物安全图景。这些数据源包括:
- 科学文献: 自动筛选全球发布的医学期刊和会议摘要,识别与特定药物相关的潜在不良事件报告 9。
- 社交媒体与公共论坛: 实时分析患者在社交网络、论坛和博客上发布的用药体验,从中捕捉可能是早期安全信号的患者自发报告 5。
- 电子健康记录(EHRs): 对大规模、纵向的患者病历数据进行分析,以发现药物暴露与不良健康结局之间的统计学关联,这对于识别罕见或迟发性不良反应尤为重要 15。
7.3 用于主动风险管理的预测模型
AI的应用正在推动药物警戒从一种“回顾性”的学科(分析已发生的事件)向一种“前瞻性”的学科(预测并预防未来事件)转变,这是提升公共健康水平的关键战略方向 4。通过训练预测模型,AI可以根据患者的特征(如年龄、合并用药、基因信息)来预测其发生特定不良事件的概率 3。这种能力不仅可以帮助医生为高风险患者选择更安全的治疗方案,还能为风险管理计划(RMPs)的制定提供数据驱动的依据。
对行业内已落地的案例进行分析可以发现,当前的应用绝大多数集中在实现“第一层次”的效率增益,即自动化常规、重复性的工作,而非实现“第二层次”的智能增益,即增强科学洞察力。在AI的营销潜力与公开记录的大规模部署之间,存在着一个明显的差距。最具体、最详实的案例,如拜耳/Genpact的合作、IQVIA的平台和辉瑞的试点项目,都围绕着案例接收和处理的自动化——数据提取、编码和录入 13。这些是高通量、劳动密集型的任务,其自动化投资回报(ROI)清晰且易于衡量 2。相比之下,更高级的应用,如基于真实世界数据的新型信号检测或预测性风险建模,虽然被频繁讨论为高潜力领域,但缺乏大规模、常态化部署的详细案例研究 18。
这揭示了行业一种深思熟虑且理性的采纳策略:先从“低垂的果实”入手。与使用“黑箱”AI模型做出新颖的科学判断相比,自动化案例处理在监管上面临的挑战相对较小。因此,企业正在采取一种分阶段的推进方式。第一阶段的目标是证明技术在定义明确、重复性任务上的可靠性、合规性和投资回报。只有在成功掌握这一阶段并与监管机构建立信任之后,企业才会进入第二阶段:将AI部署于更复杂的、需要高度判断力的活动,如因果关系评估和新型信号检测。这种谨慎的渐进策略本身就是一种组织层面的风险管理。
此外,尽管行业对AI的效率提升有着强烈的定性描述,但在公开的案例中普遍缺乏具体的量化效率指标(例如,“处理时间减少30%”或“成本节约40%”)。这背后可能有多重原因。一方面,这可能源于企业对保持竞争优势的敏感性。另一方面,这也反映了在一个复杂的、受严格监管的流程中,衡量AI端到端真实影响的内在困难。由IQVIA赞助的一项IDC调查显示,在药物警戒自动化项目的成功衡量标准中,成本降低排名最后,而合规性(55%)和实时洞察(47%)则位居前列 2。
这表明,评估AI解决方案时,企业应警惕那些仅关注成本节约的供应商宣传。真正的商业论证必须建立在一个平衡的记分卡之上,该记分卡应包括合规依从性、数据质量改进和洞察速度等多个维度,而不仅仅是运营效率。在药物警戒领域,AI投资的首要回报可能在于风险的降低,而非单纯的成本削减。
第四部分:合规与有效部署的战略框架
本部分是报告的战略核心,将监管要求和行业经验整合为一个可操作的、实用的实施框架。
第八章:验证不可预测性:为AI/ML调整计算机化系统验证(CSV)
8.1 传统CSV的局限性
经典的安装确认(IQ)、运行确认(OQ)和性能确认(PQ)验证模型是为确定性的、静态的软件系统设计的 59。对于本质上是概率性的、并且其性能可能随时间变化的AI/ML系统(即“模型漂移”),这套传统方法显得力不从心 61。AI的引入,使得验证从静态的、人力密集型的工作流,转变为适应性的、智能驱动的系统 59。
8.2 现代化的AI验证框架
因此,需要一个全新的验证框架,它既要整合GAMP 5(良好自动化生产实践指南5)等成熟的行业原则,又要满足AI的特殊需求 63。这个框架必须是基于风险的,并重点关注以下几个方面:
- 数据完整性与治理 (Data Integrity and Governance): 验证的起点是数据。这包括对数据来源、提取-转换-加载(ETL)过程、数据标注程序以及确保数据具有代表性且无偏倚的措施进行全面记录 61。ALCOA+原则在此环节至关重要,必须确保用于决策的数据是可信的 46。
- 模型选择与开发 (Model Selection and Development): 必须记录选择特定算法的科学依据。验证过程需要确认所选模型适合其预期用途,并且基于训练数据能够达到预期的技术性能 64。
- 性能评估 (Performance Evaluation): 使用独立的、具有代表性的测试数据集来评估模型的性能。评估应涵盖一系列关键性能指标,如准确率、灵敏度、特异性和精确度,并提供相应的置信区间,以量化模型性能的不确定性 61。
- 可解释性 (Explainability): 对于高风险应用,AI模型解释其决策过程的能力(即可解释性AI,XAI)对于获得监管机构的信任和实现有效的人类监督至关重要 65。一个无法解释其结论的“黑箱”模型,在GxP环境中是难以被接受的。
8.3 生命周期管理:持续监控与再验证
AI验证不是一次性的活动,而是一个持续的过程。必须制定一个健全的计划来管理模型的整个生命周期:
- 性能漂移检测 (Performance Drift Detection): 在生产环境中持续监控模型的性能指标,以及时发现因输入数据分布变化等原因导致的性能下降 61。
- 变更控制 (Change Control): 建立正式的变更控制流程,用于管理对算法、训练数据或软件环境的所有更新。任何变更都必须经过影响评估,并进行相应的再验证 60。
- 定期再验证 (Periodic Revalidation): 明确定义触发模型再训练和再验证的条件(例如,性能低于预设阈值、监管要求变更)和具体程序,以确保模型始终“适用其预期用途” 61。
第九章:治理、运营与人类监督
9.1 为AI制定健全的标准操作程序(SOPs)
企业必须更新现有的药物警戒SOPs,或创建新的SOPs,以专门管理AI系统的使用 20。这些SOPs是确保一致性、可追溯性和合规性的基础,必须清晰地定义:
- AI辅助流程的工作流: 详细描述AI辅助下的每个步骤,例如AI辅助的案例接收和编码流程,包括决策点和系统参考 20。
- 人机交互的角色与职责: 明确与系统互动的人员(如PV专员、医学审查员)的职责,以及他们在何时、如何干预AI的决策 68。
- 质量控制与性能指标: 规定强制性的质量控制步骤、数据标准(如MedDRA版本控制)以及用于衡量AI系统性能的关键绩效指标(KPIs)20。
- 异常处理程序: 制定处理AI系统错误、输出结果不确定或系统停机等异常情况的预案。
- SOP的持续维护: 建立一个流程,定期审查和更新SOPs,以使其与不断变化的全球监管要求保持一致 20。
9.2 实施“人在环路中”(HITL)模型
人类监督是监管机构的一项不可协商的期望,也是最重要的风险缓解工具 66。根据任务的风险级别和AI的自主性,可以实施不同程度的人类监督模型:
- 人在环路中 (Human-in-the-Loop, HITL): 在此模型中,AI的每一个输出或决策在最终确定前都必须经过人类的审查和批准。这是最高级别的监督,适用于风险最高的任务,例如对严重不良事件报告的最终因果关系评估或向监管机构的提交 72。
- 人在环路之上 (Human-on-the-Loop, HOTL): 在此模型中,AI系统在大多数情况下自主运行,但会将其置信度较低的输出或识别出的异常情况标记出来,交由人类进行干预。这种模型在效率和监督之间取得了平衡,适用于高通量、风险相对较低的任务,如初步的案例分类或从结构化表格中提取数据 73。
- 人机协同指挥 (Human-in-Command, HIC): 在此模型中,AI扮演顾问的角色,为人类决策者提供分析、见解或建议,但最终的决策权完全掌握在人类手中。这适用于需要复杂判断和战略考量的任务,如信号评估和风险管理计划的制定 73。
9.3 管理数据隐私与安全
药物警戒数据包含高度敏感的个人健康信息,AI系统的应用必须严格遵守全球数据隐私法规。
- GDPR(欧盟): 要求数据处理具有合法的法律基础、遵循数据最小化原则、实施“设计隐私保护”,并保障数据主体的各项权利,如被告知权、访问权和获得对自动化决策的有意义解释的权利 10。
- HIPAA(美国): 《健康保险流通与责任法案》要求对电子受保护健康信息(ePHI)实施行政、物理和技术上的安全保障措施 10。
- 最佳实践: 企业必须从系统设计之初就融入隐私保护原则(Privacy by Design),实施严格的数据最小化策略,对传输中和静态的数据进行加密,建立基于角色的访问控制,并在可能的情况下使用数据匿名化或假名化等技术来降低隐私风险 76。
第十章:化解核心风险:偏倚、可解释性与问责制
10.1 算法偏倚的挑战
AI模型的性能完全取决于其训练数据。如果训练数据本身就反映了现实世界医疗系统中的偏见(例如,某些人口群体的药物不良反应报告率偏低),那么AI模型不仅会学习并复制这些偏见,甚至可能将其放大 78。这可能导致AI系统在这些代表性不足的人群中漏掉重要的安全信号,从而构成严重的患者安全风险 78。应对这一挑战的策略包括:精心策划和构建多样化、具有代表性的数据集;定期对模型进行偏倚审计;以及采用“公平性感知”的机器学习技术来主动纠正偏倚 68。
10.2 可解释性AI(XAI)的重要性
为了让监管机构、临床医生和药物警戒专家信任AI的输出(例如,一个新发现的潜在安全信号),他们需要理解AI得出该结论的“理由”。“黑箱”模型因其决策过程不透明,是监管接受度的主要障碍 18。可解释性AI(XAI)技术旨在提供对模型内部决策逻辑的洞察,例如,通过高亮显示影响最终预测的关键输入特征。这不仅增强了透明度,也使得人类能够进行有意义的审查和验证,从而建立起对AI系统的信任 65。
10.3 建立清晰的问责制
当一个由AI辅助的流程出现失误时,责任归属问题至关重要。全球监管法规对此的立场是明确的:药品上市许可持有人(MAH)或申办方对药物警戒体系的整体运行和患者安全负有最终、不可推卸的责任 31。这份责任不能被委托给AI供应商或算法本身。这一法律现实要求企业必须建立强有力的治理结构、清晰的文档记录和有效的人类监督机制,以确保每一个由AI辅助的决策都是可追溯、可辩护的 70。
“人在环路中”(HITL)及其变体,不仅仅是一个简单的质量控制步骤,它是整个AI在药物警戒领域监管与合规战略中不可或缺的核心支柱。它是使AI这项概率性、动态的技术在严格的GxP环境中变得可接受的关键机制。AI的核心风险在于其概率性、潜在的偏倚和固有的不透明性。全球监管机构,如FDA和EMA,都强制要求采用基于风险的方法,并将人类监督作为关键的风险缓解措施 11。FDA的“模型影响力”评估指标,会因人类监督的加强而直接降低;EMA的“以人为本”原则更是其监管哲学的基石 28。
实施具体的HITL模型(人在环路中、人在环路之上等)正是将这一监管原则转化为实际操作的途径 73。这种人类监督直接应对了AI的核心风险:人类专家能够发现并纠正由数据偏倚导致的错误输出,能够对异常结果要求解释,并能够提供机器无法提供的、最终的、可问责的判断。
因此,HITL工作流的设计是AI实施过程中最关键的战略决策,它绝非一个附加功能。验证计划(第八章)、SOPs(第九章)和风险缓解策略(第十章)都必须围绕所选的HITL模型进行构建。在监管核查中,整个AI赋能的药物警戒体系的可辩护性,将取决于公司能否展示并记录其拥有一个强健、有效且定义明确的人类监督体系。
第五部分:未来展望与战略建议
本部分综合报告的全部发现,提供前瞻性视角,并为企业制定清晰、可行的实施路线图。
第十一章:药物警戒的未来与最终建议
11.1 监管协调的趋势
尽管当前全球主要监管机构的AI框架在细节上有所不同,但长远来看,国际协调是必然趋势。诸如ICH和国际药品监管机构联盟(ICMRA)等国际组织,将在推动未来AI标准统一方面发挥关键作用,它们将以ICH E6等现有指南为基础,逐步建立全球公认的AI应用原则 12。这种协调将有助于降低跨国企业的合规成本和复杂性。
11.2 向主动、预测性监测的转变
药物警戒的长期愿景是实现从被动反应到主动预测的范式转变。未来的理想状态是,AI系统能够持续不断地监控全球范围内的真实世界数据,利用预测模型在新药上市的早期甚至上市前就预见潜在的不良事件风险,从而在危害发生之前采取预防措施 7。这将是药物警戒对公共卫生的终极贡献,真正实现从“警戒”到“预警”的升华。
11.3 企业关键建议:实施路线图
为了在符合合规性的前提下有效利用AI Agent,企业应采取一个系统化、分阶段的战略方法。以下是一个七步路线图,旨在指导企业成功部署AI技术:
- 建立跨职能治理机构 (Establish a Cross-Functional Governance Body): 成立一个由药物警戒、质量、法规、IT、数据科学和法务等部门代表组成的AI指导委员会。该委员会将负责制定和监督公司的整体AI战略,确保技术实施与业务目标、风险管理和合规要求保持一致 68。
- 从基于风险的用例优先级排序开始 (Start with a Risk-Based Use Case Prioritization): 遵循行业内已验证的谨慎路径,从高通量、低风险的任务开始,例如自动化处理来自结构化表格的案例接收。这有助于团队积累经验,在风险可控的环境中验证技术平台,并向管理层展示切实的投资回报。在成功驾驭这些基础应用之后,再逐步扩展到信号检测、风险预测等更高风险、更复杂的领域。
- 从第一天起就为合规而设计 (Design for Compliance from Day One): 将监管要求(如FDA的7步框架、EMA的原则)和GxP标准嵌入到AI系统的设计和开发阶段,而不是将其视为项目结束时的一个验证环节。这包括从数据采集到模型部署的每一个环节都考虑数据完整性、可追溯性和安全性 61。
- 采纳“人类监督优先”的心态 (Adopt a “Human-in-the-Loop First” Mentality): 将所有AI工作流都围绕一个明确定义的人类监督模型来构建。根据任务的风险评估,审慎地选择HITL、HOTL或HIC模型,并将这一决策及其理由详细记录在验证计划中。人类监督是确保AI系统在GxP环境中合规、安全运行的核心保障。
- 投资于数据质量和稳健的数据治理框架 (Invest in Data Quality and a Robust Data Governance Framework): 深刻认识到任何AI系统的性能、可靠性和合规性都完全取决于其基础数据的质量、完整性和代表性。必须建立严格的数据治理流程,包括数据源验证、数据清洗、偏倚检测和数据生命周期管理 35。
- 尽早并频繁地与监管机构沟通 (Engage with Regulators Early and Often): 积极利用FDA的EDSTP和EMA的科学建议等渠道,在项目早期就与监管机构就创新的AI应用、验证策略和风险评估方法进行沟通。这种前瞻性的互动有助于获得监管机构的宝贵反馈,降低后期审批的不确定性 26。
- 培养具备AI素养的专业团队 (Develop a Competent, AI-Literate Workforce): 对药物警戒专员、临床医生和质量保证人员进行系统性培训,使他们不仅了解AI的能力,更要深刻理解其局限性(如偏倚、不确定性)。只有这样,他们才能有效地履行监督职责,做出明智的判断,并确保AI技术真正服务于患者安全这一最终目标 78。